在本案例中,我们首先介绍依存句法树的概念,然后介绍基于转移的依存句法分析,最后利用pyhanlp使用依存句法分析进行意见抽取。
1 依存句法树¶
依存句法树关注的是句子中词语之间的语法联系,并且将其约束为树形结构,词与词之间存在主从关系,这是一种二元不等价的关系。
如果一个词修饰另一个词,则称修饰词为从属词,被修饰的词为支配词,两者之间的语法关系称为依存关系。
- 主谓关系:主语修饰谓语
- 动宾关系:宾语修饰动词
- 定中关系:定于修饰中心语
- 状中关系:状语修饰中心语
- $\ldots$
将一个句子中所有词语的依存关系以有向边的形式表示出来,就会得到一棵树,称为依存句法树。
语言学家Robinson对依存句法树提了4个约束性的公理:
- 有且只有一个词语(ROOT,虚拟根节点,简称虚根)不依存于其它词语
- 除此之外所有单词必须依存于其它词语
- 每个单词不能依存于多个单词
- 如果单词A依存于B,那么位置出于A和B之间的单词C只能依存于A、B或AB之间的单词
这4条公理分别约束了依存句法树的根节点唯一性、连通性、无环性和投射性。这些约束对语料库的标注以及依存句法分析器的设计奠定了基础。
2 基于转移的依存句法分析¶
我们以“人 吃 鱼”这个句子为例子,手动构建依存句法树。
- 从“吃”连线到“人”建立依存关系,主谓关系。
- 从“吃”连线到“鱼”建立依存关系,动宾关系。
如此,我们将一棵依存句法树的构建过程表示为两个动作。如果模型能够根据句子的某些特征准确地预测这些动作,那么计算机就能够根据这些动作拼装出正确的依存句法树。这种拼装动作称为转移( transition),而这类算法统称为基于转移的依存句法分析。
我们先定义一台虚拟的机器,这台机器根据自己的状态和输入的单词,预测下一步要执行的转移动作,最后根据转移动作拼装句法树。
2.1 Arc-Eager 转移系统¶
一个转移系统$S$由4个部件构成:$S=(C,T,c_s,C_t)$。其中
- $C$是系统状态的集合
- $T$是所有可执行的转移动作的集合,每个转移动作可视为输入输出都为系统状态的函数
- $c_s$是一个初始化函数,将一个句子转换为一个初始的系统状态
- $C_t\subset C$为一系列终止状态,系统进入这些状态后即可停机输出最终的动作序列
而系统状态又由 3 元组构成: $c = (\sigma,\beta,A)$ 其中:
- $\sigma$为一个存储单词的栈
- $\beta$为存储单词的队列
- $A$为已确定的依存弧的集合
栈(stack)又名堆栈,它是一种运算受限的线性表。限定仅在表尾进行插入和删除操作的线性表。这一端被称为栈顶,相对地,把另一端称为栈底。向一个栈插入新元素又称作进栈、入栈或压栈,它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素;从一个栈删除元素又称作出栈或退栈,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。
对于上面“人 吃 鱼”的句子,Arc-Eager 的执行步骤如下:

系统转移到6号状态时,栈已经清空,队列中的单词仅剩下虚根,满足停机条件,所以算法终止。此时集合 A 中的依存弧为一棵依存句法树。
2.2 Static和Dynamic Oracle¶
对基于转移的依存句法分析器而言,它学习和预测的对象是一系列转移动作。然而依存句法树库是一棵树,并不是现成的转移动作序列。这时候就需要一个算法将语料库中的依存句法树转移为正确地转移动作序列。这种正确的转移动作序列称为规范。
动态规范:不显示地输出唯一规范,而是让机器学习模型自由试错,一旦无法拼装出正确语法树,则惩罚模型。
至于如何判断一个状态 c 执行某个动作后是否可以抵达正确语法树,我们只需根据该动作以及该状态的栈与队列进行判断即可。
训练句法分析器的步骤如下:
- 读入一个训练样本,提取特征,创建 ArcEager 的初始状态 c。
- 若 c 不是终止状态,反复进行转移序列,修正参数。
- 算法终止,返回返回模型参数 w。
3 基于依存句法分析的意见抽取¶
本节就来利用依存句法分析实现一个意见抽取的例子,提取下列商品评论中的属性和买家评价。
材质很柔软,配送也不慢,唯一差劲的是客服,态度很不好。
为了提取“材质”“配送”“客服”和“态度”所对应的意见,朴素的处理方式是在分司和词性标注之后编写正则表达式,提取名词后面的形容词。然而正则表达式无法处理“长的是待机”这样句式灵活的例子。
这时就可以对这句话进行依存句法分析,分析代码如下:
from pyhanlp import * # 导入pyhanlp包
KBeamArcEagerDependencyParser = JClass('com.hankcs.hanlp.dependency.perceptron.parser.KBeamArcEagerDependencyParser') # 调用第三方Java的依存句法分析包
parser = KBeamArcEagerDependencyParser() # 依存句法分析函数
tree = parser.parse("材质很柔软,配送也不慢,唯一差劲的是客服,态度很不好。") # 进行依存句法分析
print(tree) # 分析结果
在如上结果中,第一列为词语的ID,第二列为词语本身,第三列为词干,第四列为词性,第五列为本地词性,第六列为形态特征,第七列为支配词序号,第八列为依存关系,第九列为依存图,第十列为其他标注。以第一个词“材质”为例,它词性为N(名词),本地词性是NN(复合名词修饰),依存于第3个词“柔软”,他们之间的依存关系为nsubj(名词性主语)。 如果想进一步了解词性标注集和依存关系标注集,可参考UD的官方网站。
随后将该句法树进行可视化。如果读者是 Windows 用户的话,可以用南京大学汤光超开发的 DependencyViewer。将上述所得到的依存句法文件 tree 以“UTF-8”编码格式存入 txt 文档,再用 DependencyViewer 读取该文档,即可完成可视化,结果如下图所示。
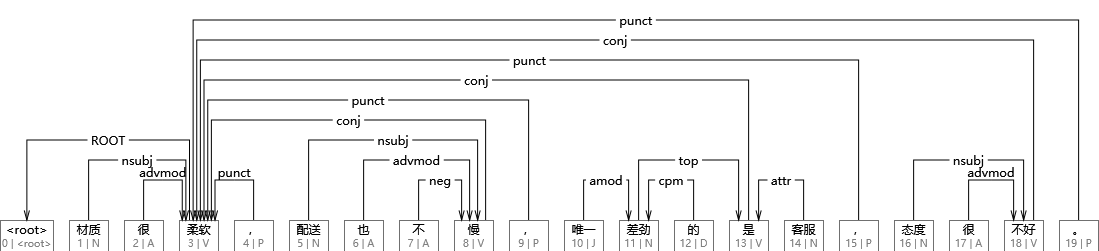
在该图中,依存弧所连接的两个词便具有依存关系。 仔细观察,不难发现与< root >相连的词为“柔软”,所以“柔软”是根节点。“材质”与“柔软”、“配送”与“慢”、“态度”与“不好”之间的依存关系都是 nsubj (名词性主语)。
利用这一规律, 不难写出第一版遍历算法,也就是用个 for 循环去遍历树中的每个节点。对于算法遍历树中的每一个词语, 如果其词性为名词且作为某个形容词的名词性主语,则认为该名词是属性,而形容词是意见。运行代码如下:
def extactOpinion1(tree): # 定义提取特性的函数
for word in tree.iterator(): # 遍历每个节点
if word.POSTAG == "NN" and word.DEPREL == "nsubj": # 如果其词性为名词且作为某个形容词的名词性主语
print("%s = %s" % (word.LEMMA, word.HEAD.LEMMA)) # 则认为该名词是属性,而形容词是意见
print("第一版")
extactOpinion1(tree) # 结果
虽然的确提取出了一些意见,然而对于配送的评价是错误的。这一版算法存在的问题之一是没有考虑到“配送不慢”这一否定修饰关系。否定修饰关系在依存句法中的标记为 neg,于是我们只需检查形容词是否存在否定修饰的支配词即可。于是得出第二版算法:
def extactOpinion2(tree): # 定义提取特性的函数
for word in tree.iterator(): # 遍历每个节点
if word.POSTAG == "NN" and word.DEPREL == "nsubj": # 如果其词性为名词且作为某个形容词的名词性主语
if tree.findChildren(word.HEAD, "neg").isEmpty(): # 检查形容词是否存在否定修饰的支配词
print("%s = %s" % (word.LEMMA, word.HEAD.LEMMA)) # 如果没有否定,则正常输出
else:
print("%s = 不%s" % (word.LEMMA, word.HEAD.LEMMA)) # 如果有否定修饰,则对形容词进行否定
print("第二版")
extactOpinion2(tree) # 结果
接下来思考如何提取“客服”的意见,“客服”与“差劲”之间的公共父节点为“是”,于是我们得到第三版算法如下:
def extactOpinion3(tree): # 定义提取特性的函数
for word in tree.iterator(): # 遍历每个节点
if word.POSTAG == "NN": # 如果其词性为名词
# 检测名词词语的依存弧是否是“属性关系”,
# 如果是,则寻找支配词的子节点中的主题词
# 以该主题词作为名词的意见。
if word.DEPREL == "nsubj": # ①属性
if tree.findChildren(word.HEAD, "neg").isEmpty(): # 检查形容词是否存在否定修饰的支配词
print("%s = %s" % (word.LEMMA, word.HEAD.LEMMA))
else:
print("%s = 不%s" % (word.LEMMA, word.HEAD.LEMMA))
elif word.DEPREL == "attr": # 不是属性关系
top = tree.findChildren(word.HEAD, "top") # ②主题
if not top.isEmpty():
print("%s = %s" % (word.LEMMA, top.get(0).LEMMA))
print("第三版")
extactOpinion3(tree)
至此,4 个属性被完整正确地提取出来了,读者可以尝试搜集更多的句子,通过分析句法结构总结更多的提取规则。
4. 总结¶
句法分析是传统NLP任务中与语言学关联最紧密的一项。在本章中,我们首先介绍了短语结构语法与依存文法等基础语言学知识。接着我们介绍了依存句法分析的基础语言学知识,并且着重学习了基于转移的依存句法分析。最后,为了展示句法分析的实际应用场景,我们利用pyhanlp,基于依存句法分析,对一个商品评论实现了意见抽取。