卷积神经网络是一类典型的处理网格型数据的深度学习结构,在图像和视频处理等领域得到了广泛的应用。本案例采用 Olivetti Faces 人脸数据集进行训练,使用 TensorFlow 构建一个深度卷积神经网络对人脸进行识别。我们发现数据增强能够显著降低总体损失,提升神经网络性能。

1 Olivetti Faces 数据集探索¶
Olivetti Faces 是由纽约大学整理的一个人脸数据集。原始数据库可从(http://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html)。 我们使用的是 Sklearn 提供的版本。该版本是纽约大学 Sam Roweis 的个人主页以 MATLAB 格式提供的。
数据集包括 40 个不同的对象,每个对象都有 10 个不同的人脸图像。对于某些对象,图像是在不同的时间、光线、面部表情(睁眼/闭眼、微笑/不微笑)和面部细节(眼镜/不戴眼镜)下拍摄。所有的图像都是在一个深色均匀的背景下拍摄的,被摄者处于直立的正面位置(可能有细微面部移动)。原始数据集图像大小为 $92 \times 112$,而 Roweis 版本图像大小为 $64 \times 64$。
首先使用 sklearn 的 datasets 模块在线获取 Olivetti Faces 数据集。
from sklearn.datasets import fetch_olivetti_faces
faces = fetch_olivetti_faces()
观察数据集结构组成:
faces
观察发现,该数据集包括四部分:
1)DESCR 主要介绍了数据的来源;
2)data 以一维向量的形式存储了数据集中的400张图像;
3)images 以二维矩阵的形式存储了数据集中的400张图像;
4)target 存储了数据集中400张图像的类别信息,类别分别为 0-39 。
下面进一步观察数据的结构与类型:
print("The shape of data:",faces.data.shape, "The data type of data:",type(faces.data))
print("The shape of images:",faces.images.shape, "The data type of images:",type(faces.images))
print("The shape of target:",faces.target.shape, "The data type of target:",type(faces.target))
可见,数据都以 numpy.ndarray 形式存储。因为下一步我们希望搭建卷积神经网络来实现人脸识别,所以特征要用二维矩阵存储的图像,这样可以充分挖掘图像的结构信息。
随机选取部分人脸,使用 matshow 函数将其可视化。
import numpy as np
rndperm = np.random.permutation(len(faces.images)) #将数据的索引随机打乱
import matplotlib.pyplot as plt
%matplotlib inline
plt.gray()
fig = plt.figure(figsize=(9,4) )
for i in range(0,18):
ax = fig.add_subplot(3,6,i+1 )
plt.title(str(faces.target[rndperm[i]]))
ax.matshow(faces.images[rndperm[i],:])
plt.box(False) #去掉边框
plt.axis("off")#不显示坐标轴
plt.tight_layout()

查看同一个人的不同人脸的特点。
labels = [2,11,6] #选取三个人
%matplotlib inline
plt.gray()
fig = plt.figure(figsize=(12,4) )
for i in range(0,3):
faces_labeli = faces.images[faces.target == labels[i]]
for j in range(0,10):
ax = fig.add_subplot(3,10,10*i + j+1 )
ax.matshow(faces_labeli[j])
plt.box(False) #去掉边框
plt.axis("off")#不显示坐标轴
plt.tight_layout()

观察发现,每一个人的不同图像都存在角度、表情、光线,是否戴眼镜等区别,这种样本之间的差异性虽然提升了分类难度,但同时要求模型必须提取到人脸的高阶特征。
将数据集划分为训练集和测试集两部分,注意要按照图像标签进行分层采样。
# 定义特征和标签
X,y = faces.images,faces.target
# 以5:5比例随机地划分训练集和测试集
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(X, y, test_size=0.5,stratify = y,random_state=0)
# 记录测试集中出现的类别,后期模型评价画混淆矩阵时需要
#index = set(test_y)
import pandas as pd
pd.Series(train_y).value_counts().sort_index().plot(kind="bar")

pd.Series(test_y).value_counts().sort_index().plot(kind="bar")
# 转换数据维度
train_x = train_x.reshape(train_x.shape[0], 64, 64, 1)
test_x = test_x.reshape(test_x.shape[0], 64, 64, 1)
2 建立卷积神经网络人脸识别模型¶
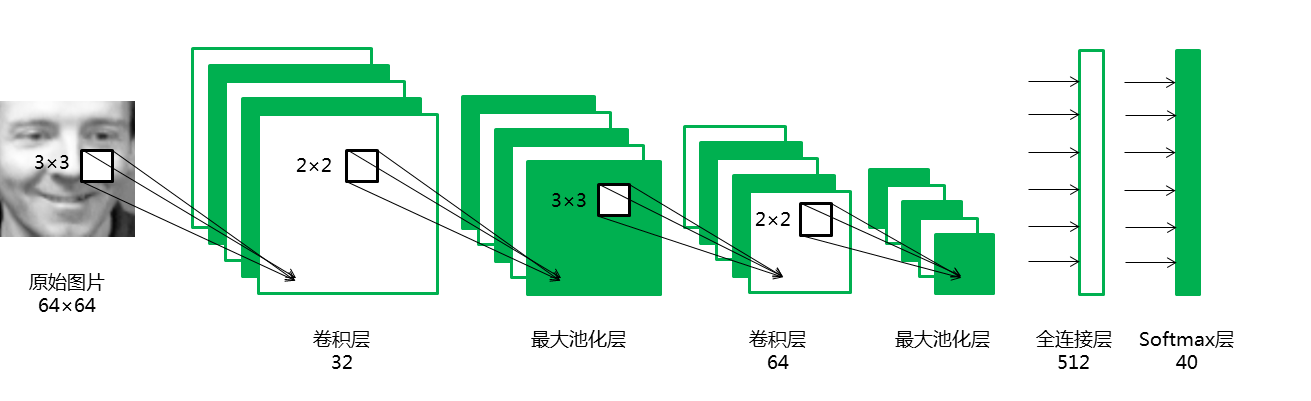
2.2 使用 TensorFlow 搭建网络模型¶
从keras的相应模块引入需要的对象。
import warnings
warnings.filterwarnings('ignore') #该行代码的作用是隐藏警告信息
import tensorflow as tf
import tensorflow.keras.layers as layers
import tensorflow.keras.backend as K
K.clear_session()
逐层搭建卷积神经网络模型。
inputs = layers.Input(shape=(64,64,1), name='inputs')
conv1 = layers.Conv2D(32,3,3,padding="same",activation="relu",name="conv1")(inputs)
maxpool1 = layers.MaxPool2D(pool_size=(2,2),name="maxpool1")(conv1)
conv2 = layers.Conv2D(64,3,3,padding="same",activation="relu",name="conv2")(maxpool1)
maxpool2 = layers.MaxPool2D(pool_size=(2,2),name="maxpool2")(conv2)
flatten1 = layers.Flatten(name="flatten1")(maxpool2)
dense1 = layers.Dense(512,activation="tanh",name="dense1")(flatten1)
dense2 = layers.Dense(40,activation="softmax",name="dense2")(dense1)
model = tf.keras.Model(inputs,dense2)
网络结构打印。
model.summary()
2.3 模型训练与评估¶
模型编译,指定误差函数、优化方法和评价指标。使用训练集进行模型训练。
model.compile(loss='sparse_categorical_crossentropy', optimizer="Adam", metrics=['accuracy'])
model.fit(train_x,train_y, batch_size=20, epochs=30, validation_data=(test_x,test_y),verbose=2)
# 模型评价
score = model.evaluate(test_x, test_y)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
3 使用 TensorFlow 进行数据增强¶
在深度学习中,为了防止过度拟合,我们通常需要足够的数据,当无法得到充分大的数据量时,可以通过图像的几何变换来增加训练数据的量。为了充分利用有限的训练集(只有320个样本),我们将通过一系列随机变换增加训练数据。
TensorFlow 提供一个图像预处理类 ImageDataGenerator 能够帮助我们进行图像数据增强,增强的手段包括图像随机转动、水平偏移、竖直偏移、随机缩放等。
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 定义随机变换的类别及程度
datagen = ImageDataGenerator(
rotation_range=0, # 图像随机转动的角度
width_shift_range=0.01, # 图像水平偏移的幅度
height_shift_range=0.01, # 图像竖直偏移的幅度
shear_range=0.01, # 逆时针方向的剪切变换角度
zoom_range=0.01, # 随机缩放的幅度
horizontal_flip=True,
fill_mode='nearest')
下面我们使用增强后的数据集训练模型:
inputs = layers.Input(shape=(64,64,1), name='inputs')
conv1 = layers.Conv2D(32,3,3,padding="same",activation="relu",name="conv1")(inputs)
maxpool1 = layers.MaxPool2D(pool_size=(2,2),name="maxpool1")(conv1)
conv2 = layers.Conv2D(64,3,3,padding="same",activation="relu",name="conv2")(maxpool1)
maxpool2 = layers.MaxPool2D(pool_size=(2,2),name="maxpool2")(conv2)
flatten1 = layers.Flatten(name="flatten1")(maxpool2)
dense1 = layers.Dense(512,activation="tanh",name="dense1")(flatten1)
dense2 = layers.Dense(40,activation="softmax",name="dense2")(dense1)
model2 = tf.keras.Model(inputs,dense2)
model2.compile(loss='sparse_categorical_crossentropy', optimizer="Adam", metrics=['accuracy'])
# 训练模型
model2.fit_generator(datagen.flow(train_x, train_y, batch_size=200),epochs=30,steps_per_epoch=16, verbose = 2,validation_data=(test_x,test_y))
# 模型评价
score = model2.evaluate(test_x, test_y)
print('Test score:', score[0])
print('Test accuracy:', score[1])
可以看到,数据增强后,模型效果得到提升。
4 总结¶
本案例我们使用一份人脸数据集,借助 TensorFlow 构建了卷积神经网络用于人脸识别,同时对比了数据增强对模型效果的影响。本案例使用的主要 Python 工具,版本和用途列举如下。如果在本地运行遇到问题,请检查是否是版本不一致导致。
| 工具包 | 版本 | 用途 |
|---|---|---|
| NumPy | 1.17.4 | 图像数据格式 |
| Pandas | 0.23.4 | 数据读取与预处理 |
| Matplotlib | 3.0.2 | 数据可视化 |
| Seaborn | 0.9.0 | 数据可视化 |
| Sklearn | 0.19.1 | 测试集训练集划分、人脸数据集加载 |
| TensorFlow | 1.12.0 | 卷积神经网络的构建与训练、数据增强 |