本案例基于人脸图像建立卷积神经网络模型用于性别分类,并分别运用多种评价指标评价模型是否存在偏见,即在不同人种下对女性的分类是否存在差异。
注:本案例由于需使用GPU,暂时无法在线上运行。
1 数据读取¶
本案例使用的UTKFace数据集是一个具有较长年龄跨度(0到116岁)的大型人脸数据集,包含20000多张面部图像,每张图像包含年龄、性别和种族的标签,图像覆盖了姿势、面部表情、光照、遮挡和分辨率等变化,可用于面部识别、年龄估计、面部定位等任务。数据集可以通过此链接下载:https://susanqq.github.io/UTKFace/
每个面部图像的标签都嵌入在文件名中,格式为:[age]_[gender]_[race]_[date&time].jpg。其中各变量的具体描述如下:
| 变量 | 描述 |
|---|---|
| 年龄[age] | 0到116之间的整数 |
| 性别[gender] | 0表示男性,1表示女性 |
| 种族[race] | 0 表示白人,1 表示黑人,2表示亚洲人,3表示印度人,4表示其它(如西班牙裔、拉丁裔、中东等) |
| 日期和时间[data&time] | 格式为yyyymmddHHMMSSFFF,显示收集到UTKFace的图像的日期和时间 |
我们希望基于这一数据集建立卷积神经网络模型用于性别分类,并运用相关评价指标评价卷积神经网络模型在不同人种下对女性的分类是否存在差异。这里,我们主要选取0和4的人种,即白人和西班牙裔、拉丁裔、中东等人种进行比较。
我们首先导入必要的库:
import glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from skimage import io
from skimage.transform import resize
并设置必要参数:
# 数据文件路径
image_dir = 'UTKFace/'
# 图片像素大小
img_size = 64
# 需要对比的人种,0为白人,4为西拉中等人种
races_to_consider = [0, 4]
# 无特权组
unprivileged_groups = [{'race': 4.0}]
# 特权组
privileged_groups = [{'race': 0.0}]
# 目标分类标签:男性
favorable_label = 0.0
# 目标分类标签:女性
unfavorable_label = 1.0
接着,我们依次读取图片文件名,将人种为0或4的图片数据分别保存在人种、性别和像素数组:
# 存储人种标签
protected_race = []
# 存储性别标签
outcome_gender = []
# 存储图片像素数组
feature_image = []
for i, image_path in enumerate(glob.glob(image_dir + "*.jpg")):
try:
# 将性别和人种分别分隔开保存在两个变量中
gender, race = image_path.split('\\')[-1].split('_')[1:3]
gender = int(gender)
race = int(race)
# 如果是我们需要的人种,则将他们的三种数据分别保存在列表中
if race in races_to_consider:
protected_race.append(race)
outcome_gender.append(gender)
# 读取图片,并设置其大小为64×64
feature_image.append(resize(io.imread(image_path), (img_size, img_size)))
except:
print("Missing: " + image_path)
从输出的路径可以看出,有三张图片标签中缺失了race变量。
# 统计男性女性的数量
outcome_gender = pd.Series(outcome_gender)
gender_count = outcome_gender.value_counts()
# 设置绘图时正常显示中文
plt.rcParams['font.sans-serif'] = ['SimHei']
# 设置绘图框
plt.figure(figsize=(8, 6))
# 绘制柱形图
gender_count.plot(kind='bar', rot=360)
# 修改横轴标签
plt.xticks([0, 1], ['男性', '女性'])
# 在柱形上方标注数量
plt.text(0, gender_count[0], gender_count[0], ha="center", va= "bottom", fontsize=10)
plt.text(1, gender_count[1], gender_count[1], ha="center", va= "bottom", fontsize=10)

从图中我们可以看出,男女几乎各占一半,不存在类别不平衡问题。
# 统计两个人种的数量
protected_race = pd.Series(protected_race)
race_count = protected_race.value_counts()
# 设置绘图框
plt.figure(figsize=(8, 6))
# 绘制柱形图
race_count.plot(kind='bar', rot=360)
# 修改横轴标签
plt.xticks([0, 1], ['白人', '其它'])
# 在柱形上方标注数量
plt.text(0, race_count[0], race_count[0], ha="center", va= "bottom", fontsize=10)
plt.text(1, race_count[4], race_count[4], ha="center", va= "bottom", fontsize=10)

# 将像素数组转换为ndarray数组
images = np.array(feature_image)
# 打印两个人种各一张图片进行观察
plt.figure(figsize=(8, 6))
# 创建第一个子绘图框
plt.subplot(1, 2, 1)
# 展示图片
plt.imshow(images[1])
# 去掉横纵轴标签
plt.xticks(())
plt.yticks(())
plt.subplot(1, 2, 2)
plt.imshow(images[-2])
plt.xticks(())
plt.yticks(())

from sklearn.model_selection import train_test_split
p_train, p_test,y_train,y_test = train_test_split(protected_race, outcome_gender,
test_size=.15, # 测试集比例15%
random_state=10, # 设置随机种子
stratify=outcome_gender) # 分层抽样
# 分割训练集和测试集
X_train = images[y_train.index]
X_test = images[y_test.index]
查看分割后训练集和测试集的目标特征分布:
print("训练集性别数量分布:"+ "\n" + str(y_train.value_counts()))
print("训练集人种数量分布:"+ "\n" + str(p_train.value_counts()))
print("测试集性别数量分布:"+ "\n" + str(y_test.value_counts()))
print("测试集人种数量分布:"+ "\n" + str(p_test.value_counts()))
3.2 模型结构介绍¶
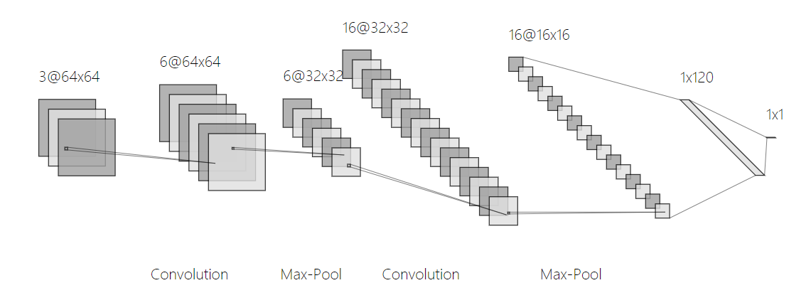
我们使用的卷积神经网络模型具体如下:
- 输入:64×64×3 ;
- 卷积层:卷积核大小3×3×3,个数为6,步长为1,填充策略为“SAME”,激活函数为ReLU,输出64×64×6 ;
- 池化层:窗口大小为2×2,步长为2,输出32×32×6 ;
- 卷积层:卷积核大小3×3×3,个数为16,步长为1,填充策略为“SAME”,激活函数为ReLU,输出32×32×16 ;
- 池化层:窗口大小为2×2,步长为2,输出16×16×16 ;
- 扁平化:将特征图拉直,便于连接全连接层,输出1×1×4096 ;
- 全连接层:120个神经元,输出1×1×120 ;
- 输出层:1个神经元,激活函数为Sigmoid,输出1×1×1。
import tensorflow as tf
from tensorflow import keras
# 初始化顺序模型类
model = keras.Sequential()
# 添加卷积层
model.add(keras.layers.Conv2D(filters=6, # 卷积核个数
kernel_size=3, # 卷积核大小
padding='same', # 填充策略
activation='relu', # 激活函数
input_shape=(64,64,3))) # 输入维度
# 添加池化层
model.add(keras.layers.MaxPooling2D(pool_size=2)) # 窗口大小
# 添加卷积层
model.add(keras.layers.Conv2D(filters=16, kernel_size=3, padding='same', activation='relu'))
# 添加池化层
model.add(keras.layers.MaxPooling2D(pool_size=2))
# 添加扁平化
model.add(keras.layers.Flatten())
# 添加全连接层
model.add(keras.layers.Dense(120, activation='relu'))
# 添加输出层
model.add(keras.layers.Dense(1, activation='sigmoid'))
# 输出模型概要
model.summary()
接着,我们定义损失函数、优化器和评价标准:
model.compile(loss='binary_crossentropy', # 损失函数为二分类交叉熵
optimizer='adam', # Adam方法
metrics=['accuracy']) # 评价标准为分类正确率
3.3 模型训练和预测¶
指定GPU进行训练:
import os
## 选择GPU 0
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
keras.backend.set_session(sess)
开始训练模型:
model.fit(X_train, # 训练集
y_train.values, # 训练集标签
batch_size=100, # batch大小
epochs=10) # 迭代轮数
最后,进行模型预测:
y_pred = pd.Series(model.predict_classes(X_test), index=y_test.index)
4 模型偏见分析¶
AI Fairness 360工具包是一个开源库,可以帮助检测和消除机器学习模型中的偏差,其Python接口包含一组全面的模型指标,用于检验模型中的偏差。
AI Fairness 360Python接口的安装:- 1.使用
conda创建一个Python 3.5的环境conda create --name aif360 python=3.5 conda activate aif360 - 2.使用
pip进行安装pip install aif360
- 1.使用
4.1 将预测结果按人种进行分组¶
我们首先封装一个函数用于将NumPy数组或其它元数据转换为aif360数据集,方便简化指标的计算和比较两个数据集:
from aif360.datasets import BinaryLabelDataset
def dataset_wrapper(outcome, protected, unprivileged_groups, privileged_groups,
favorable_label, unfavorable_label):
df = pd.DataFrame(data=outcome,
columns=['outcome'])
df['race'] = protected
dataset = BinaryLabelDataset(favorable_label=favorable_label,
unfavorable_label=unfavorable_label,
df=df,
label_names=['outcome'],
protected_attribute_names=['race'],
unprivileged_protected_attributes=unprivileged_groups)
return dataset
利用封装好的函数进行数据集的转换,用于后续指标计算:
# 转换训练集标签
original_traning_dataset = dataset_wrapper(outcome=y_train, protected=p_train,
unprivileged_groups=unprivileged_groups,
privileged_groups=privileged_groups,
favorable_label=favorable_label,
unfavorable_label=unfavorable_label)
# 转换测试集标签
original_test_dataset = dataset_wrapper(outcome=y_test, protected=p_test,
unprivileged_groups=unprivileged_groups,
privileged_groups=privileged_groups,
favorable_label=favorable_label,
unfavorable_label=unfavorable_label)
# 转换预测结果
plain_predictions_test_dataset = dataset_wrapper(outcome=y_pred, protected=p_test,
unprivileged_groups=unprivileged_groups,
privileged_groups=privileged_groups,
favorable_label=favorable_label,
unfavorable_label=unfavorable_label)
4.2 评价指标计算¶
最后,我们在测试集上计算相关的偏差评价指标:
from aif360.metrics import ClassificationMetric
classified_metric_nodebiasing_test = ClassificationMetric(original_test_dataset,
plain_predictions_test_dataset,
unprivileged_groups=unprivileged_groups,
privileged_groups=privileged_groups)
TPR = classified_metric_nodebiasing_test.true_positive_rate()
TNR = classified_metric_nodebiasing_test.true_negative_rate()
bal_acc_nodebiasing_test = 0.5*(TPR+TNR)
# 评价结果
print("Test set: Classification accuracy = %f" % classified_metric_nodebiasing_test.accuracy())
print("Test set: Balanced classification accuracy = %f" % bal_acc_nodebiasing_test)
print("Test set: Statistical parity difference = %f" % classified_metric_nodebiasing_test.statistical_parity_difference())
print("Test set: Disparate impact = %f" % classified_metric_nodebiasing_test.disparate_impact())
print("Test set: Equal opportunity difference = %f" % classified_metric_nodebiasing_test.equal_opportunity_difference())
print("Test set: Average odds difference = %f" % classified_metric_nodebiasing_test.average_odds_difference())
print("Test set: Theil index = %f" % classified_metric_nodebiasing_test.theil_index())
print("Test set: False negative rate difference = %f" % classified_metric_nodebiasing_test.false_negative_rate_difference())
其中,测试集分类正确率为0.853341,Statistical parity difference为负数说明,白人人种中识别为女性的概率更高,Disparate impact进一步表明其它人种中识别为女性的概率要比白人的低大约0.2,False negative rate difference表明其它人种中女性被预测错误的比例要大一些。
5 案例总结¶
建立了卷积神经网络模型用于性别分类,比较不同人种下对女性分类的差异;
通过计算三种评价指标,发现:
模型在其它人种中识别女性的概率要低于在白人中识别女性的概率;
其它人种中女性被预测错误的比例要比白人的高;
模型存在一定偏见,
原因之一是因为训练集中大部分为白人,其它人种占比较小。