网络爬虫是一种从互联网上进行开放数据采集的重要手段。本案例通过使用Python的相关模块,开发一个简单的爬虫。实现从某图书网站自动下载感兴趣的图书信息的功能。主要实现的功能包括单页面图书信息下载,图书信息抽取,多页面图书信息下载等。本案例适合大数据初学者了解并动手实现自己的网络爬虫。
1、任务描述和数据来源¶
从当当网搜索页面,按照关键词搜索,使用Python编写爬虫,自动爬取搜索结果中图书的书名、出版社、价格、作者和图书简介等信息。
当当搜索页面:http://search.dangdang.com/
2、单页面图书信息下载¶
2.1 网页下载¶
Python中的 requests 库能够自动帮助我们构造向服务器请求资源的request对象,返回服务器资源的response对象。如果仅仅需要返回HTML页面内容,直接调用response的text属性即可。在下面的代码中,我们首先导入requests库,定义当当网的搜索页面的网址,设置搜索关键词为"机器学习"。然后使用 requests.get 方法获取网页内容。最后将网页的前1000个字符打印显示。
import requests #1. 导入requests 库
test_url = 'http://search.dangdang.com/?key='+ '机器学习' #2. 设置网页的URL地址
content_page = requests.get(test_url).text #3. 执行页面请求,返回页面内容
print(content_page[:1000]) #4.将页面的前1000个字符打印显示出来
2.2 图书内容解析¶
下面开始做页面的解析,分析源码.这里我使用Chrome浏览器直接打开网址 http://search.dangdang.com/?key=机器学习 。然后选中任意一本图书信息,鼠标右键点击“检查”按钮。不难发现搜索结果中的每一个图书的信息在页面中为<li>标签,如下图所示:
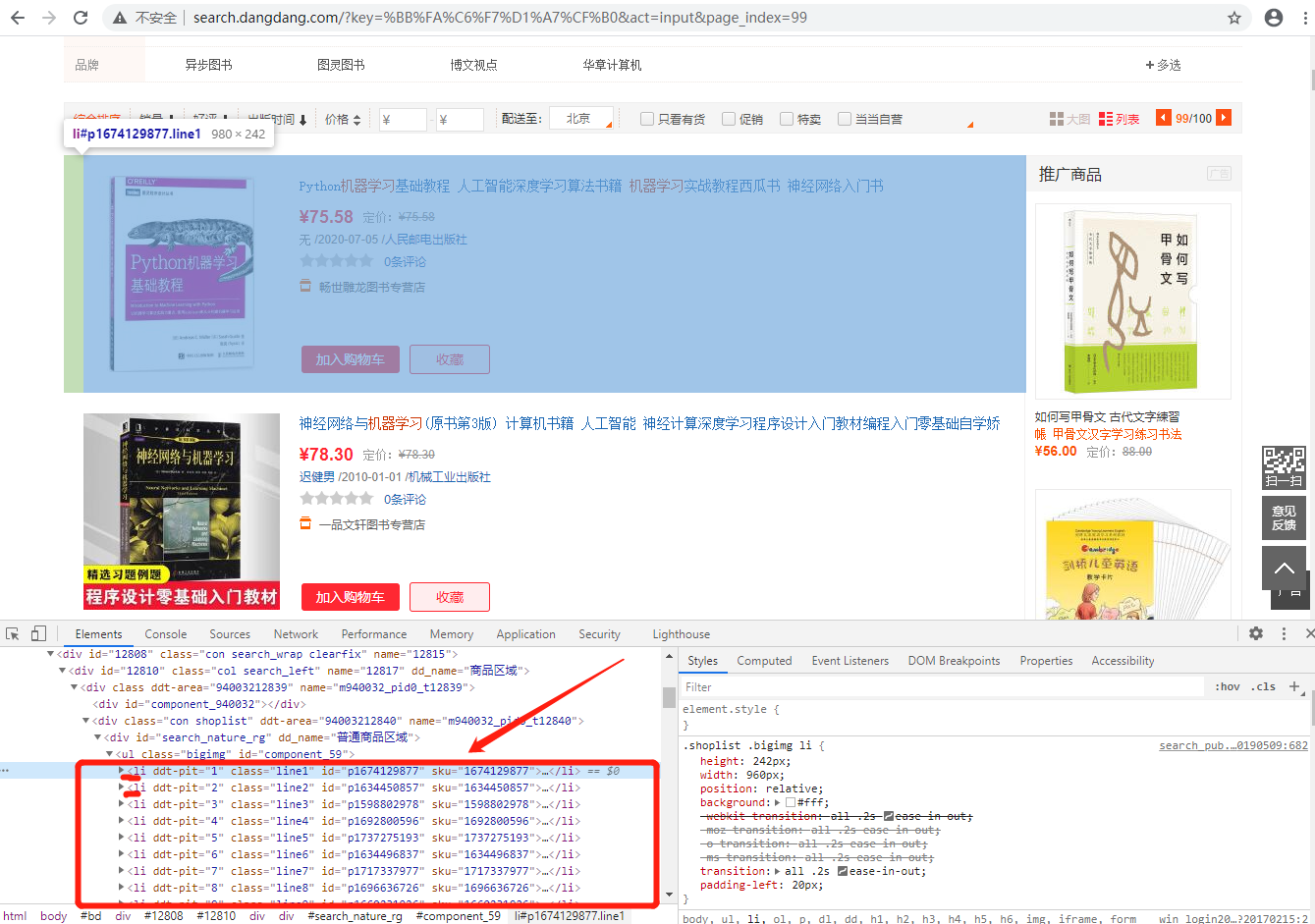
点开第一个<li>标签,发现下面还有几个<p>标签,且class分别为"name"、"detail"、"price"等,这些标签下分别存储了商品的书名、详情、价格等信息。

我们以书名信息的提取为例进行具体说明。点击 li 标签下的 class属性为 name 的 p 标签,我们发现书名信息保存在一个name属性取值为"itemlist-title"的 a 标签的title属性中,如下图所示:

我们可以使用xpath直接描述上述定位信息为 //li/p/a[@name="itemlist-title"]/@title 。下面我们用 lxml 模块来提取页面中的书名信息。xpath的使用请参考 https://www.w3school.com.cn/xpath/xpath_syntax.asp 。
from lxml import etree #导入etree模块
page = etree.HTML(content_page) #将页面字符串解析成树结构
book_name = page.xpath('//li/p/a[@name="itemlist-title"]/@title') #用xpath提取出书名信息。
book_name[:10] #打印提取出的前10个书名信息
同理,我们可以提取图书的出版信息(作者、出版社、出版时间等),当前价格、星级、评论数等更多的信息。这些信息对应的xpath路径如下表所示。
| 信息项 | xpath路径 |
|---|---|
| 书名 | //li/p/a[@name="itemlist-title"]/@title |
| 出版信息 | //li/p[@class="search_book_author"] |
| 当前价格 | //li/p[@class="price"]/span[@class="search_now_price"]/text() |
| 星级 | //li/p[@class="search_star_line"]/span[@class="search_star_black"]/span/@style |
| 评论数 | //li/p[@class="search_star_line"]/a[@class="search_comment_num"]/text() |
下面我们编写一个函数 extract_books_from_content,输入一个页面内容,自动提取出页面包含的所有图书信息。
from lxml import etree
def extract_books_from_content(content_page):
books = []
page = etree.HTML(content_page)
book_name = page.xpath('//li/p/a[@name="itemlist-title"]/@title') #书名
pub_info = page.xpath('//li/p[@class="search_book_author"]')#出版信息
pub_info = [book_pub.xpath('string(.)') for book_pub in pub_info]
price_now = page.xpath('//li//span[@class="search_now_price"]/text()')#当前价格
stars = page.xpath('//li/p[@class="search_star_line"]/span[@class="search_star_black"]/span/@style') #星级
comment_num = page.xpath('//li/p[@class="search_star_line"]/a[@class="search_comment_num"]/text()') #评论数
for book in zip(book_name, pub_info, price_now, stars, comment_num):
books.append(list(book))
return books
books = extract_books_from_content(content_page)
books[:5]
为了显示的方便,我们将上述提取到的图书信息转换成 Pandas 的 DataFrame 格式。
import pandas as pd
books_df = pd.DataFrame(data=books,columns=["书名","出版信息","当前价格","星级","评论数"])
books_df[:10]
books_df.shape
2.3 图书数据存储¶
上一小节我们已经成功从网页中提取出了图书的信息,并且转换成了 DataFrame 格式。可以选择将这些图书信息保存为 CSV 文件,Excel 文件,也可以保存在数据库中。这里我们使用 DataFrame 提供的 to_csv 方法保存为CSV文件。
books_df.to_csv("./input/books_test.csv",index=None)
3、多页面图书信息下载¶
观察搜索页面最底部,输入一个关键词,通常会返回多页结果,点击任意一个页面按钮,然后观察浏览器地址栏的变化。我们发现不同页面通过浏览器URL中添加 page_index 属性即可。例如我们搜索"机器学习"关键词,访问第10页结果,则使用以下URL:
http://search.dangdang.com/?key=机器学习&page_index=10
假设我们一共希望下载10页内容,则可以通过以下代码实现。
import time
key_word = "机器学习" #设置搜索关键词
max_page = 10 #需要下载的页数
books_total = []
for page in range(1,max_page+1):
url = 'http://search.dangdang.com/?key=' + key_word + "&page_index=" + str(page) #构造URL地址
page_content = requests.get(url).text #下载网页内容
books = extract_books_from_content(page_content) #网页图书信息解析
books_total.extend(books) #将当前页面的图书信息添加到结果列表
print("page " + str(page) +", "+ str(len(books)) + " books downloaded." )
time.sleep(10) #停顿10秒再下载下一页
转换成DataFrame格式。
books_total_df = pd.DataFrame(data=books_total, columns=["书名","出版信息","当前价格","星级","评论数"])
随机抽样5个图书显示。
books_total_df.sample(5)
books_total_df.shape
将图书信息保存为文件。
books_total_df.to_csv("./input/books_total.csv",encoding="utf8",sep="\t",index=None)
4 总结和展望¶
借助Python的 requests, lxml, Pandas等工具,我们已经实现了一个简单的网络爬虫。能够从当当网按照关键词搜索图书,将图书信息页面下载,并从页面中解析出结构化的图书信息。最后将解析出的图书信息保存为了CSV格式的文件。
你能够修改本案例的代码,通过设置其他关键词,下载你自己感兴趣的图书信息吗?
本案例中,我们设置下载页数为10,你有什么办法能够自动获取返回的页面数量?