包版本信息¶
#encoding=utf-8
#!pip freeze | grep genius
#!pip freeze | grep jieba
import jieba , genius
print ["jieba version : ", jieba.__version__]
数据准备¶
将案例中提到的中文文本保存在变量word_text中,并导入中文分词第三方库jieba和genius。jieba基于前缀词典,从句子中构建词图,生成有所有可能的词所构成的有向无环图;对于未登录词,采用隐马尔科夫模型进行识别。而genius则是采用条件随机场算法进行中文分词。
import jieba
import genius
word_text = u'''加强专业人才培养。创新人才培养模式,建立健全多层次、多类型的大数据人才培养体系。鼓励高校设立数据科学和数据工程相关专业,重点培养专业化数据工程师等大数据专业人才。
鼓励采取跨校联合培养等方式开展跨学科大数据综合型人才培养,大力培养具有统计分析、计算机技术、经济管理等多学科知识的跨界复合型人才。鼓励高等院校、职业院校和企业合作,加强职业技能人才实践培养,积极培育大数据技术和应用创新型人才。'''
print word_text
中文分词模型¶
中文分词¶
本案例将结合文本描述如何对中文文本进行分词。而对于奇异词和未登录词的识别是中文分词重点关注的问题。对于模型而言,未登录词就是未知的新词。判断一组汉字是否应作为一个词整体出现,需要结合上下文的语境,以及其他方面的知识,模型算法无法做到完全自动化,不需要人为干预。目前,比较成熟的未登录词识别技术包括常见的中文人名识别等。
在具体分词的过程中,未登录词通常在文本经过第一次分词模型处理后,作为两两相邻的词组出现。事实上,未登录词的识别过程就是寻找相邻但实际不需要切分的词组, 然后将它们连接起来作为整体的词出现。
从另外一个角度来看,中文分词实质上是一个标注文本中每个字符的过程。因此,我们可以将字符的标签分为四类
| B | M | E | S |
|---|---|---|---|
| 词的开始 | 词的中间 | 词的结束 | 单个字符(汉字)的词 |
举例来说,对句子我爱北京天安门进行分词后的结果为我/爱/北京/天安门。根据字符的标签,我们还可以将分词结果表达为我S爱S北B京E天B安M门E
那么对这句话来说,,也就是说,我们要通过“你现在应该去幼儿园了”这个观察序列来确定状态序列,也就是HMM的“解码问题”。比如这句话的解码结果就是:“SBEBESBMES”。
如果我们把字符的标签看作字符所在的状态,字符为可观察的字符序列,那么我们可以通过观察字符序列来去确定字符的状态序列。因此,我们可以使用隐马尔科夫模型和条件随机场模型来记性中文分词,也就是序列标注。
分词技术¶
- 隐马尔科夫模型
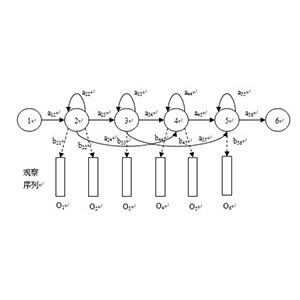
隐马尔科夫模型将分词的结果看作是模型隐含状态的序列,通过观察字符序列来确定隐含状态序列,就是因马尔科夫模型的解码问题。
回顾一下,隐马尔可夫模型$model = (A, B, \omega)$的主要参数
状态值集合 $Q$
观测值集合 $O$
转移概率矩阵 $A$
发射概率矩阵 $B$
初始状态分布 $\Omega$
解码(decoding)问题的具体形式为:
已知模型model与观测值序列M,求解使得条件概率$P(N|M)$最大化的状态序列$N$。
- 条件随机场
隐马尓可夫模型在计算条件概率$P(N|M)$的前提假设为特征独立性,这会让模型无法考虑上下文和语境的信息。条件随机场则很好的地决了这一问题。
条件随机场模型仍然把中文分词看作字符标注问题。使用条件随机场模型进行中文分词的过程就是将句子中的字符标注后,把标签B和标签E之间的字,以及标注为S的单个字符作为一个整体的分词。
条件随机场(Conditional Random Field)在自然语言处理中的应用集中在以下场景:
分词(切分完整的句子,将其转变为词的集合)
词性标注(标注分词的词性,比如说动词,名词等)
命名实体识别(识别人名,地名等具有一定规律的词)
第三方库实现¶
- jieba
jieba分词库会主要使用函数cut()来实现中文分词的过程。cut()函数的主要输入参数为将要进行分词的文本,其中cut_all表明是否在全局模式或者精确模式之间切换。
在cut()函数的内部,再次调用__cut()函数,实现隐马尔科夫模型。更进一步来说,__cut()函数会调用viterbi算法求出输入文本对应的隐含状态序列,然后基于隐含状态序列分词。
seg_list = jieba.cut(word_text, cut_all=True)
## 全模式
print u"全模式: \n"
print "/ ".join(seg_list)
在全模式下,cut()函数返回了所有可能的分词组合,比如人才/ 人才培养/ 培养/ 体系/。当然,我们还可以切换为精确模式,给出模型认为最有的分词组合。
seg_list = jieba.cut(word_text, cut_all=False)
## 精确模式
print u"精确模式: \n"
print "/ ".join(seg_list)
从结果上来看,jieba将大数据这个名词,分割为大和数据两个独立的词。这显示是不符合现实规则的。在jiebe中,我们科通过调整词频,让模型可以将大数据整体识别出类。
jieba.suggest_freq(u'大数据', True)
seg_list = jieba.cut(word_text, cut_all=False)
## 认为干预
print u"人为调整词频: \n"
print "/ ".join(seg_list)
- genius
在genius中,seg_text()负责具体的中文分词过程,该函数有多种参数可供选择
| 参数 | 说明 |
|---|---|
| use_combine | 使用字典进行词合并 |
| use_pinyin | 对拼音进行分词处理 |
| use_tagging | 进行词性标注 |
| use_break | 对分词结构打断处理 |
在这里,我们需要注意的是输入参数的中文文本必须要是unicode编码。
接下来,我们举例说明。使用的中文文本为
鼓励高校设立数据科学和shuju工程相关专业,重点培养专业化数据工程师等大数据专业rencai
常见的词性对照表为
| 词性缩写 | 说明 |
|---|---|
| v | 动词 |
| j | 简称略语 |
| n | 名词 |
| w | 标点符号 |
| d | 副词 |
| a | 形容词 |
| c | 连词 |
| e | 叹词 |
sample_text = u'''鼓励高校设立数据科学和shuju工程相关专业,重点培养专业化数据工程师等大数据专业人才。'''
seg_list = genius.seg_text(sample_text,
use_combine = True,
use_break = False,
use_tagging = True,
use_pinyin_segment = False)
print '\n'.join(['%s\t%s' % (word.text, word.tagging) for word in seg_list])
我们把参数use_pinyin_segment的取值设为True, use_tagging的取值设为False。
seg_list = genius.seg_text(sample_text,
use_combine = True,
use_break = False,
use_tagging = False,
use_pinyin_segment = True)
print '\n'.join([word.text for word in seg_list])
了解参数的基本设置之后,我们对word_text进行中文分词。
seg_list = genius.seg_text(word_text,
use_combine = True,
use_break = False,
use_tagging = False,
use_pinyin_segment = False)
print u'使用CRF模型进行中文分词: \n'
print '/ '.join([word.text for word in seg_list])
而seg_keywords()函数则是genius库中的另外一种分词函数,分词的结果保留了歧义的分词组合,类似于jieba粉刺中cut()函数的全模式。该分词函数的分词结果多适用于搜索引擎。
seg_list = genius.seg_keywords(sample_text,
use_break = True,
use_tagging = True,
use_pinyin_segment = False,
use_combine = False)
print '\n'.join(['%s\t%s' % (word.text, word.tagging) for word in seg_list])
从输出结果上来看,大数据给出了多种可能的分词组合。然后,我们使用word_text文本,查看分词结果。
seg_list = genius.seg_keywords(word_text,
use_break = True,
use_tagging = False,
use_pinyin_segment = False,
use_combine = False)
print '\ '.join([word.text for word in seg_list])
当然,genius还提供了从文本中提取关键词的函数extract_tag()函数。保持参数的默认值不变,我们尝试从word_text中提取关键词。
tag_list = genius.extract_tag(word_text)
print('\ '.join(tag_list))
对于genius来说,用来训练条件随机场模型的预料来自于新闻类文章,出自1998年1月份的人民日报。我们知道,条件虽进场模型的效果愈来愈训练预料的类别和文本覆盖度。因此,提高语料的质量(标准版)可以进一步提升分词模型的准确度。